Attaching package: 'ggdag'The following object is masked from 'package:stats':
filter
Digging Deeper
Potential Outcomes
\[ Y_i = \begin{cases} Y_i(1) & \text{if } D_i = 1 \text{ (treatment group)} \\ Y_i(0) & \text{if } D_i = 0 \text{ (control group)} \end{cases} \]
Treatment Effect for individual \(i\)
\[ TE_i = Y_i(1) - Y_i(0) \]
Fundamental Problem of Causal Inference
Counterfactuals
\[ \widehat{ATE} = \overline{Y}_{treatment\_group} - \overline{Y}_{control\_group} \]
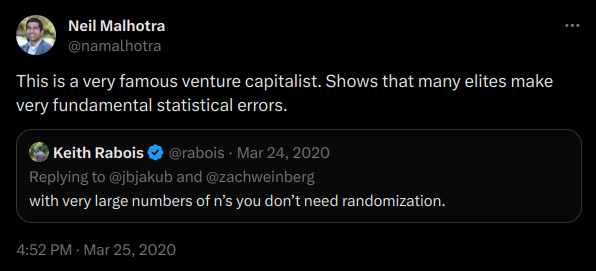
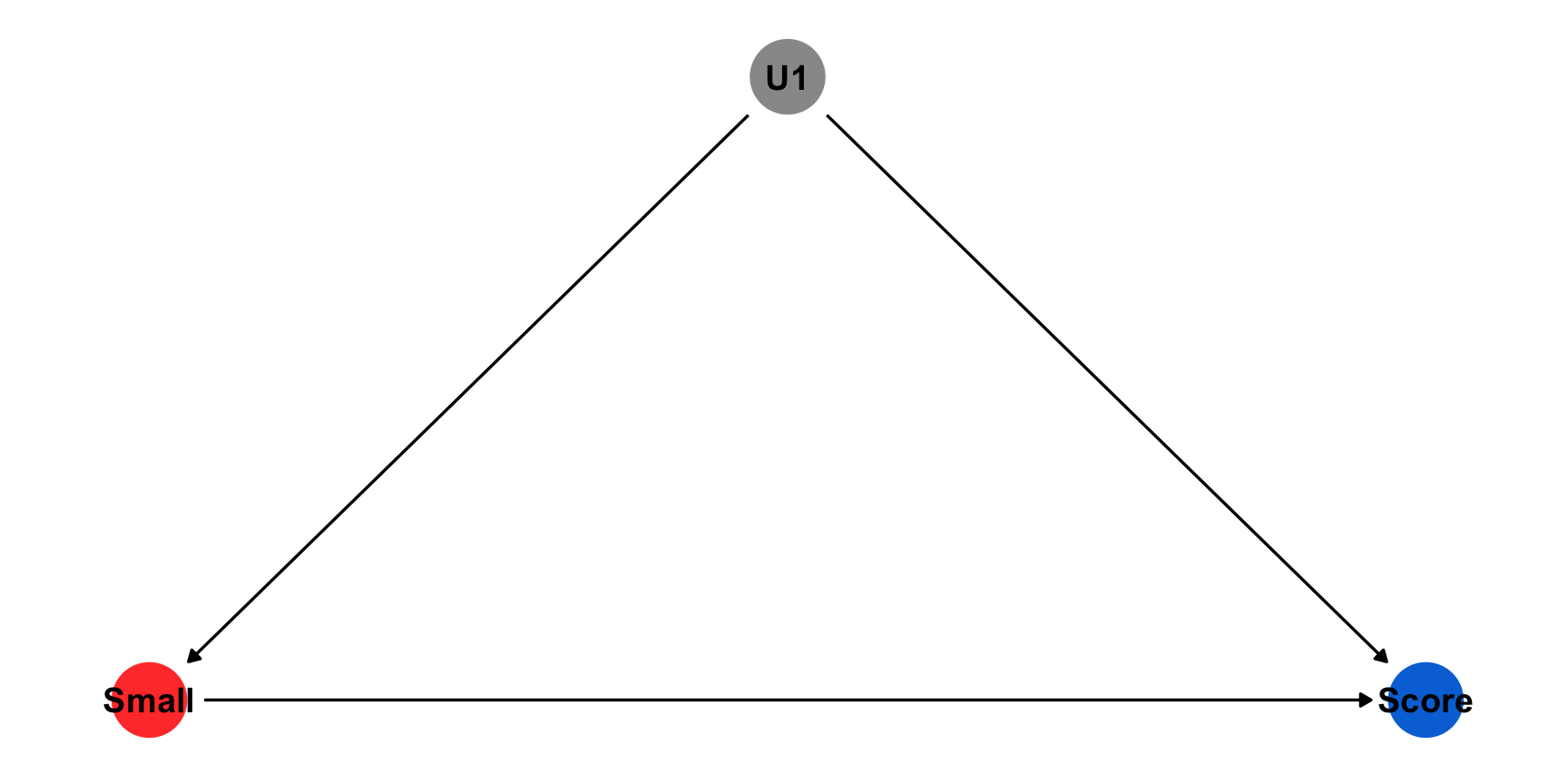
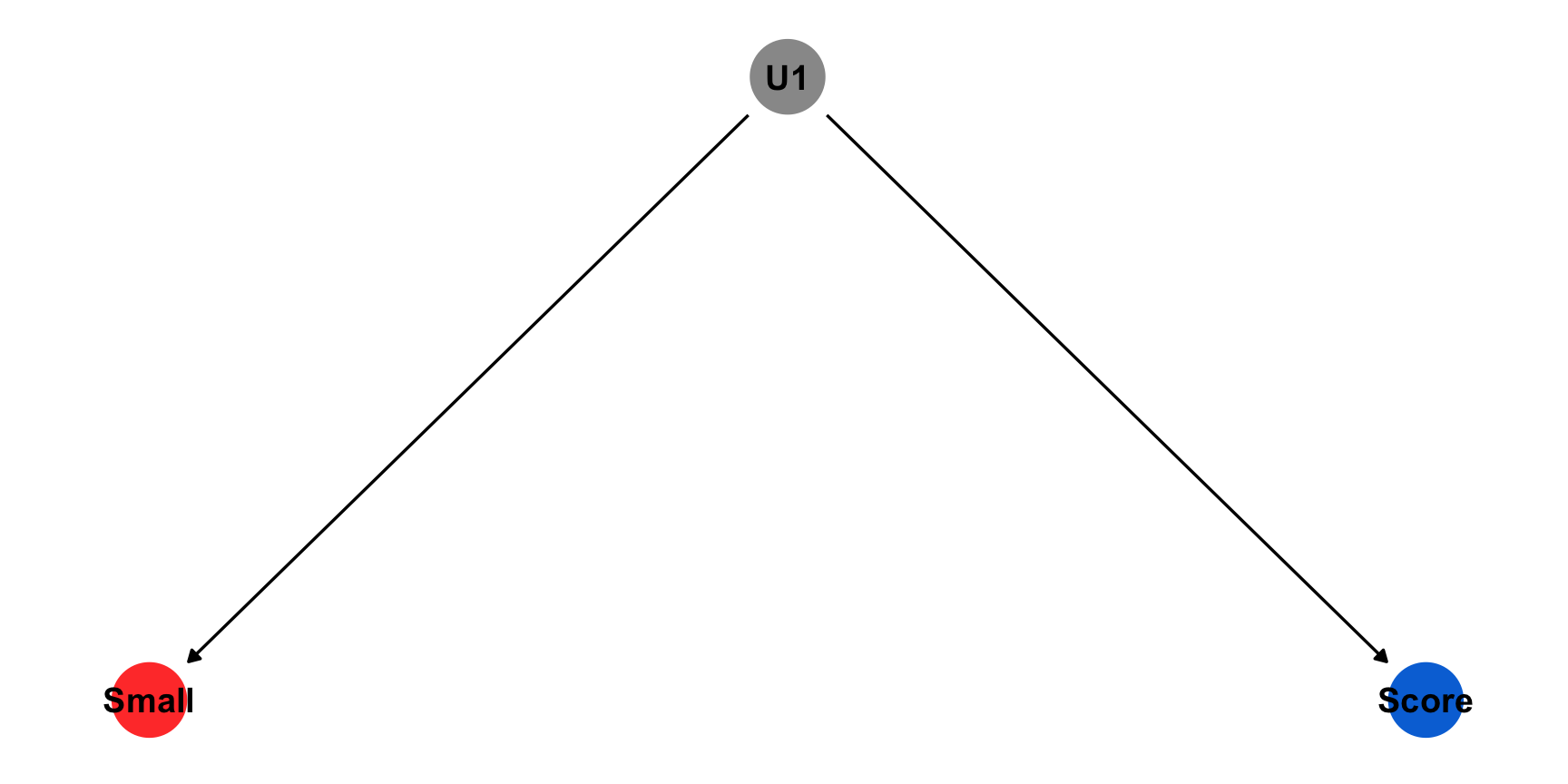
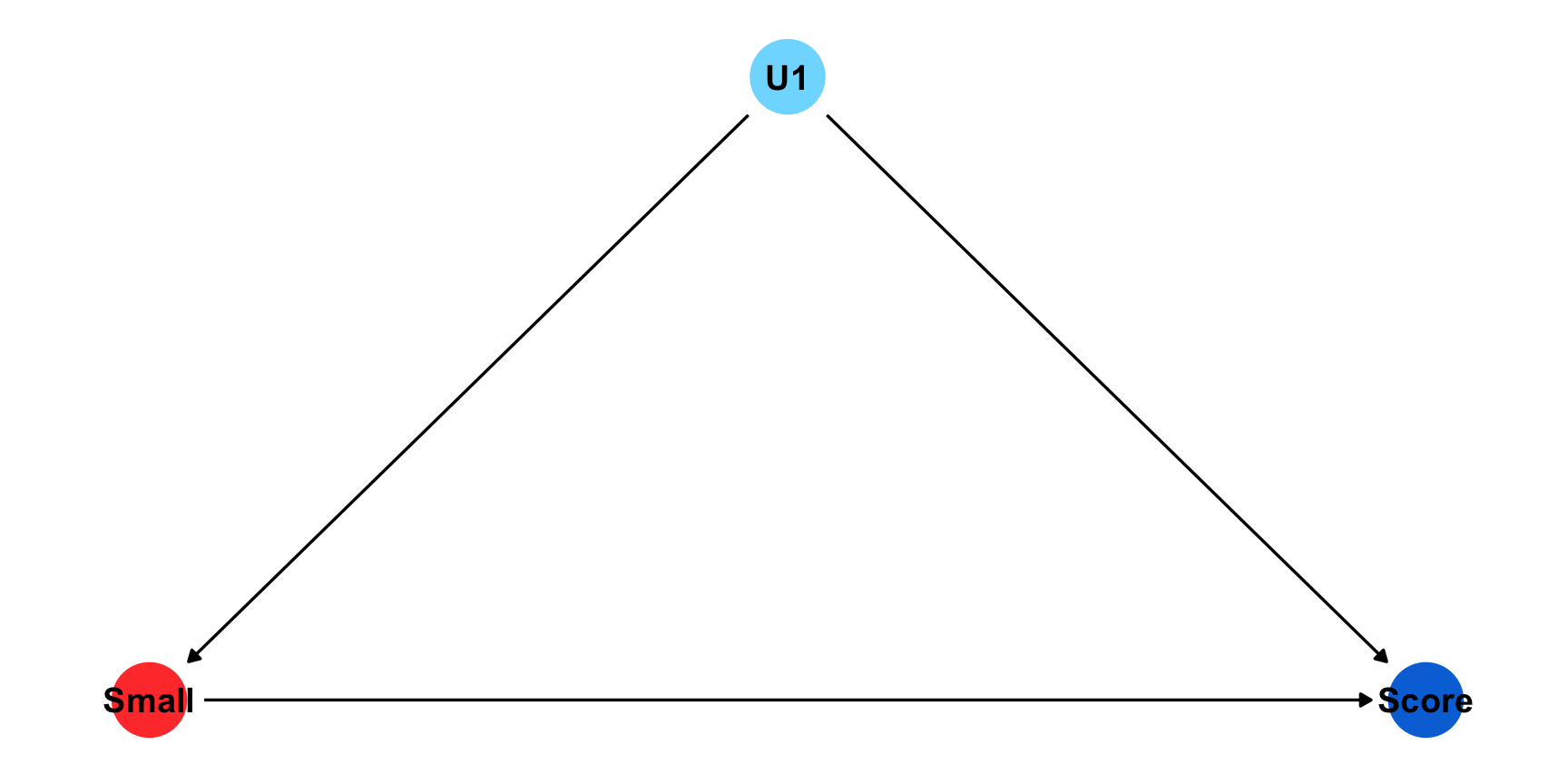
Example: What is the effect of class size on test scores
Attaching package: 'ggdag'The following object is masked from 'package:stats':
filter
library(ggplot2)
Year = c(0,1,2,3)
Outcome = c(NA, 1.3, 1.7,NA)
Treatment = c("Control", "Control","Control","Control")
dat = data.frame(Year, Outcome, Treatment)
ggplot(data = dat, aes(x = Year, y = Outcome, group = Treatment, color = Treatment)) +
geom_line(aes(linetype=Treatment),size=2) +
geom_point(size = 6) +
scale_linetype_manual(values=c("solid")) +
xlim(0,3) +
scale_y_continuous(limits = c(1,1.85), breaks = seq(1, 1.85, by = .1)) +
scale_color_manual(values = c("blue") ) +
theme(legend.position = "none", text = element_text(size=20)) 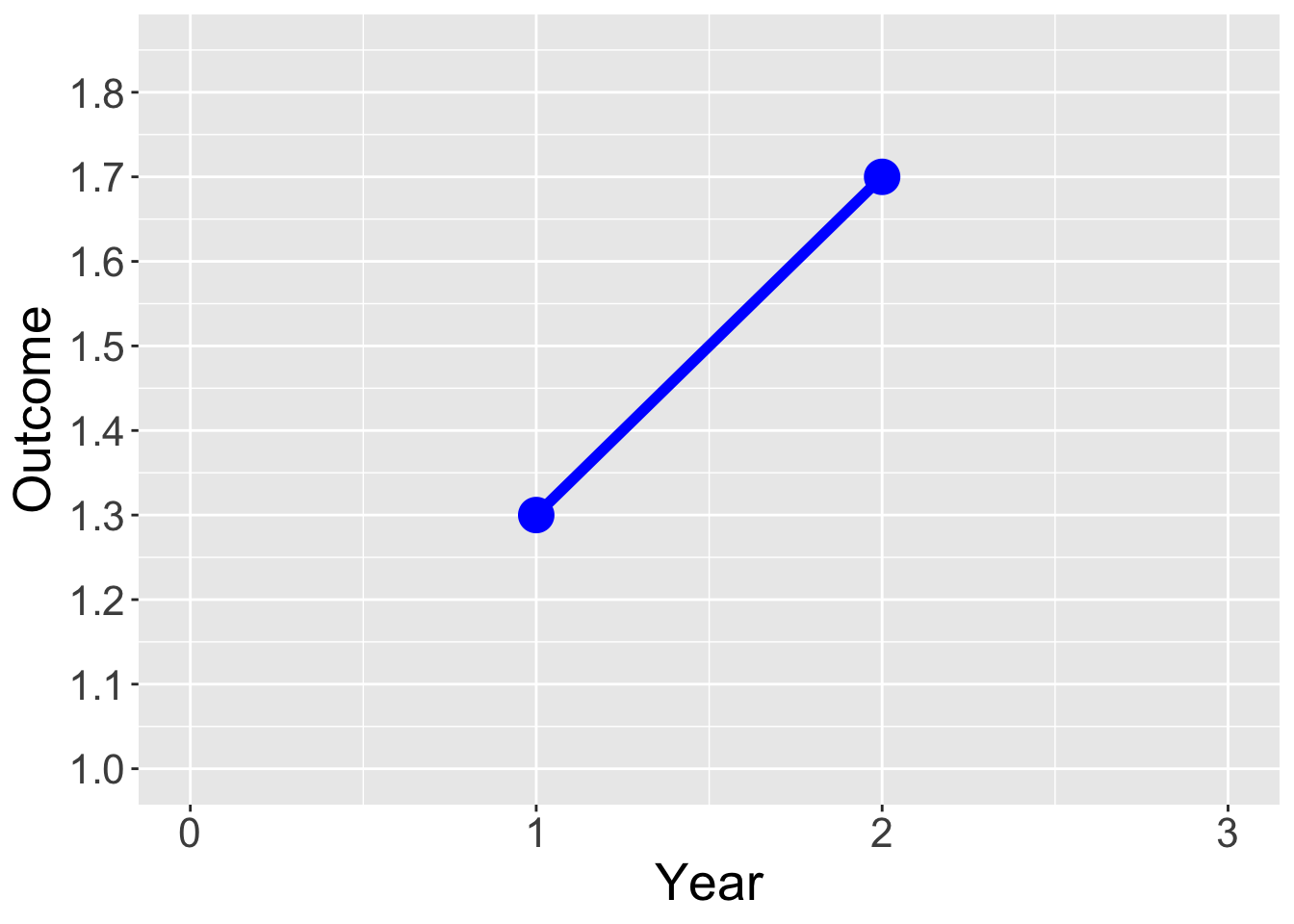
Year = c(0,1,2,3)
Outcome = c(0.9, 1.3, 1.7, 2.1)
Treatment = c("Control", "Control","Control","Control")
dat = data.frame(Year, Outcome, Treatment)
ggplot(data = dat, aes(x = Year, y = Outcome, group = Treatment, color = Treatment)) +
geom_line(aes(linetype=Treatment),size=2) +
geom_point(size = 6) +
xlim(0,3) +
scale_y_continuous(breaks = seq(1, 1.85, by = .1)) +
scale_linetype_manual(values=c("solid", "solid")) +
scale_color_manual(values = c("blue") ) +
coord_cartesian(ylim = c(1, 1.85), clip = "on") +
theme(legend.position = "none", text = element_text(size=20))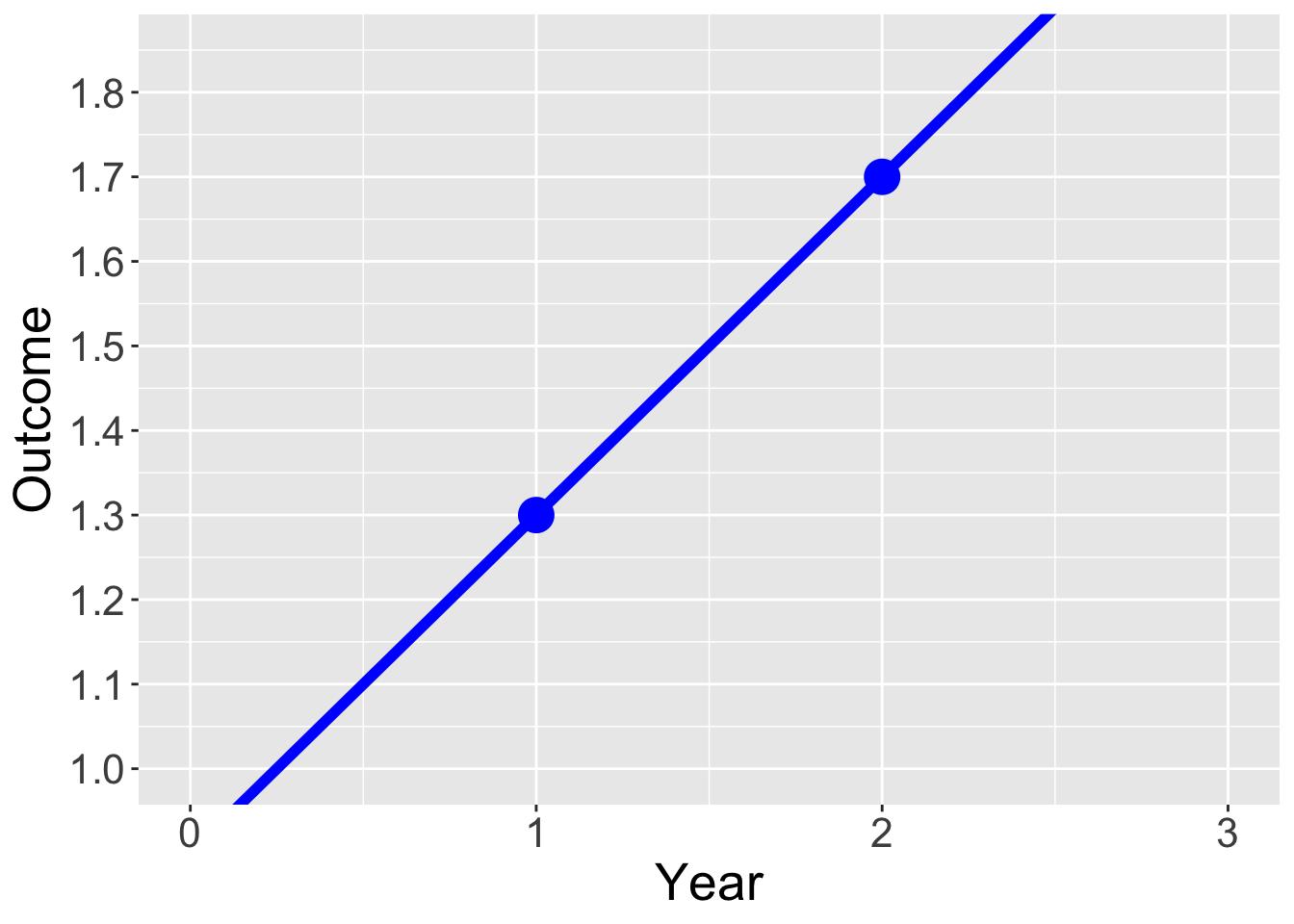
Year = c(0,1,2,3)
Outcome = c(NA, 1.2, 1.4, NA,
NA, 1.3, 1.7, NA)
Treatment = c("Control", "Control","Control","Control",
"Treatment", "Treatment", "Treatment", "Treatment")
dat = data.frame(Year, Outcome, Treatment)
ggplot(data = dat, aes(x = Year, y = Outcome, group = Treatment, color = Treatment)) +
geom_line(aes(linetype=Treatment),size=2) +
geom_point(size = 6) +
xlim(0,3) +
scale_y_continuous(limits = c(1,1.85), breaks = seq(1, 1.85, by = .1)) +
scale_linetype_manual(values=c("solid", "solid")) +
scale_color_manual(values = c("red", "blue") ) +
theme(legend.position = c(0.8, 0.2), text = element_text(size=20))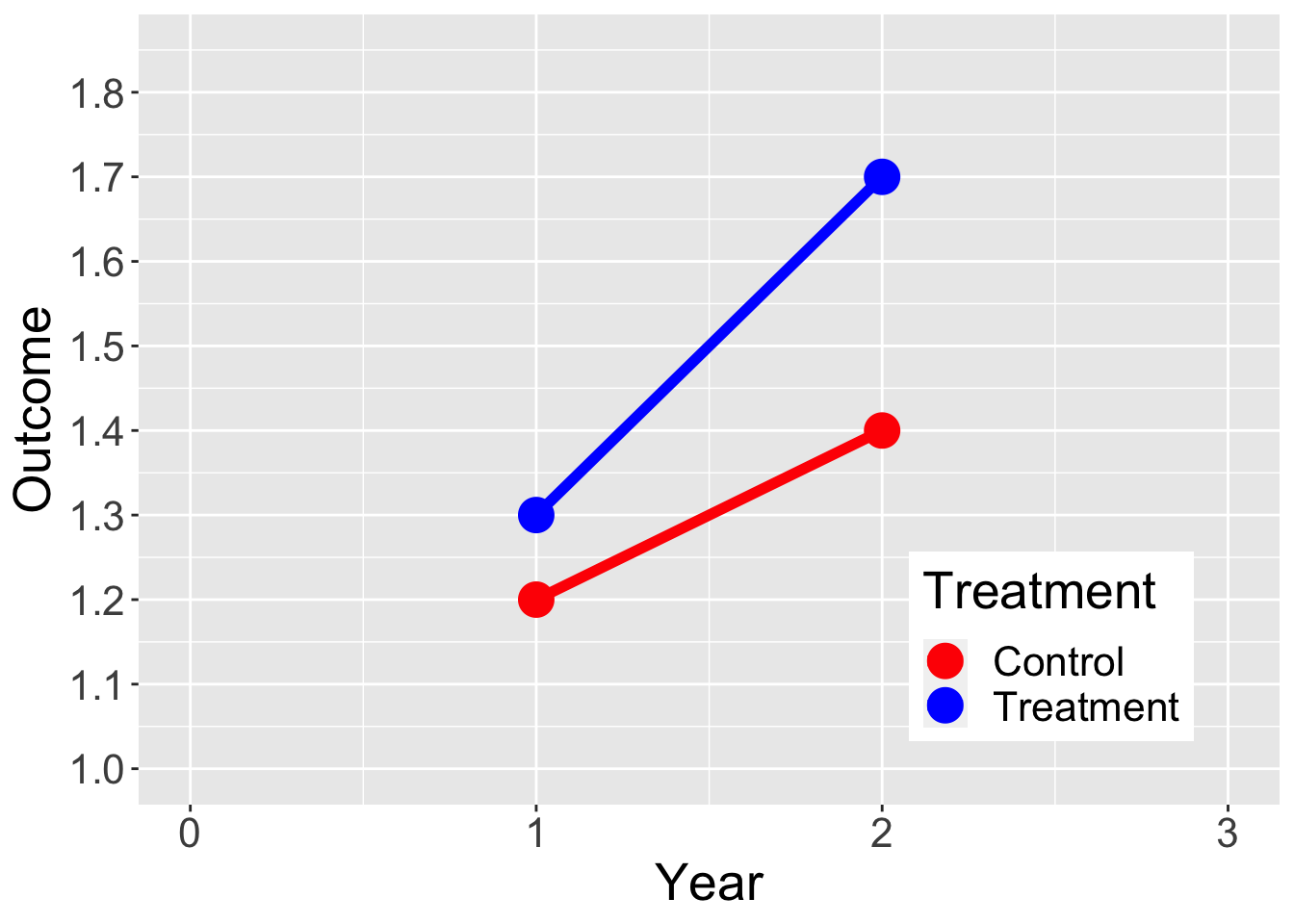
Year = c(0,1,2,3)
Outcome = c(1, 1.2, 1.4, 1.6,
0.9, 1.3, 1.7, 2.1)
Treatment = c("Control", "Control","Control","Control",
"Treatment", "Treatment", "Treatment", "Treatment")
dat = data.frame(Year, Outcome, Treatment)
ggplot(data = dat, aes(x = Year, y = Outcome, group = Treatment, color = Treatment)) +
geom_line(aes(linetype=Treatment),size=2) +
geom_point(size = 6) +
xlim(0,3) +
scale_y_continuous(breaks = seq(1, 1.85, by = .1)) +
scale_linetype_manual(values=c("solid", "solid")) +
scale_color_manual(values = c("red", "blue") ) +
coord_cartesian(ylim = c(1, 1.85), clip = "on") +
theme(legend.position = c(0.8, 0.2), text = element_text(size=20))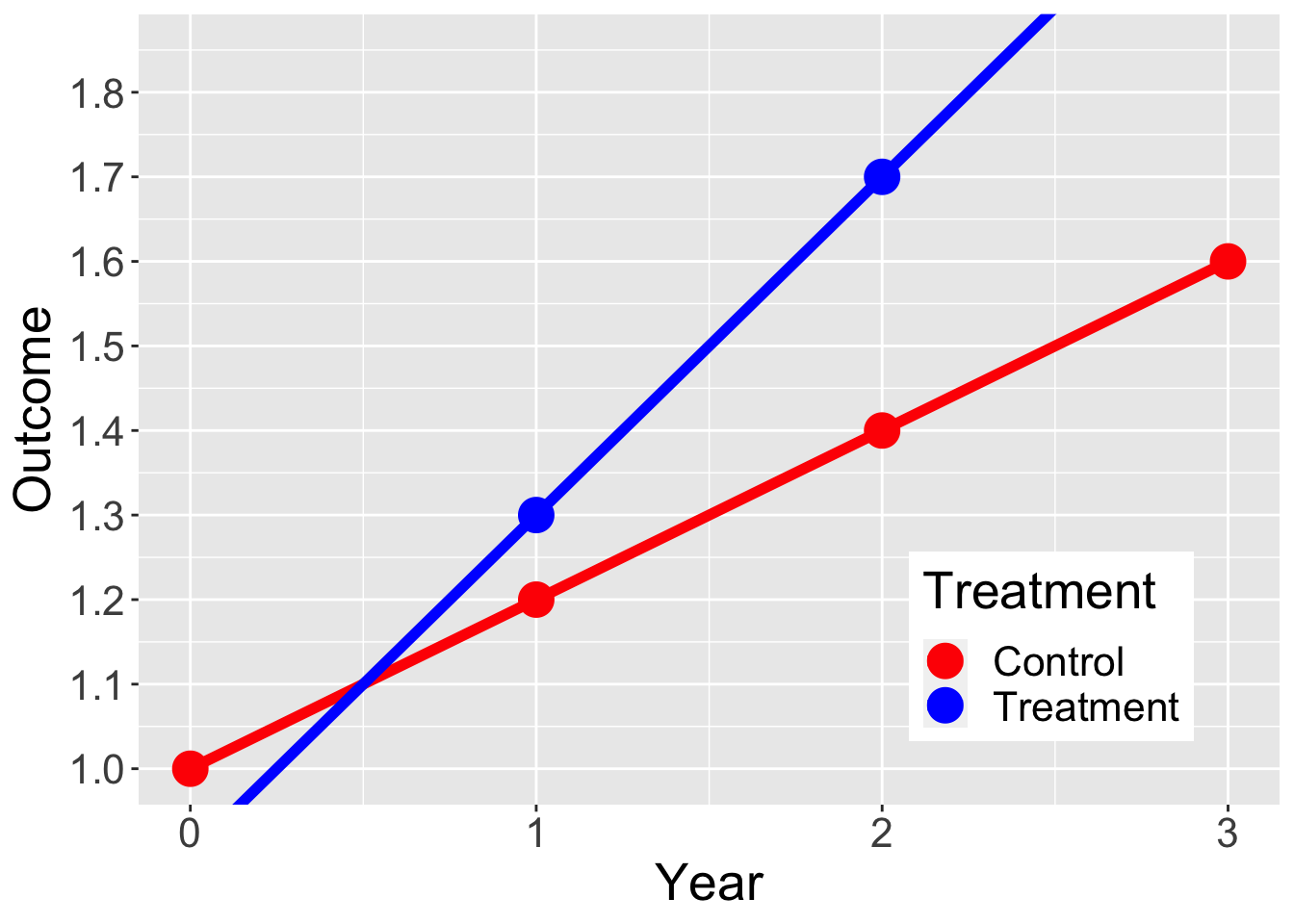
Year = c(0,1,2,3)
Outcome = c(NA, 1.2, 1.4, NA,
NA, 1.3, 1.7, NA,
NA, 1.3, 1.5, NA)
Treatment = c("Control", "Control","Control","Control",
"Treatment", "Treatment", "Treatment", "Treatment",
"Comparison","Comparison","Comparison","Comparison")
dat = data.frame(Year, Outcome, Treatment)
ggplot(data = dat, aes(x = Year, y = Outcome, group = Treatment, color = Treatment)) +
geom_line(aes(linetype=Treatment),size=2) +
geom_point(size = 6) +
xlim(0,3) +
scale_y_continuous(limits = c(1,1.85), breaks = seq(1, 1.85, by = .1)) +
scale_linetype_manual(values=c("dotted", "solid", "solid")) +
scale_color_manual(values = c("black", "red", "blue") ) +
theme(legend.position = c(0.8, 0.2), text = element_text(size=20))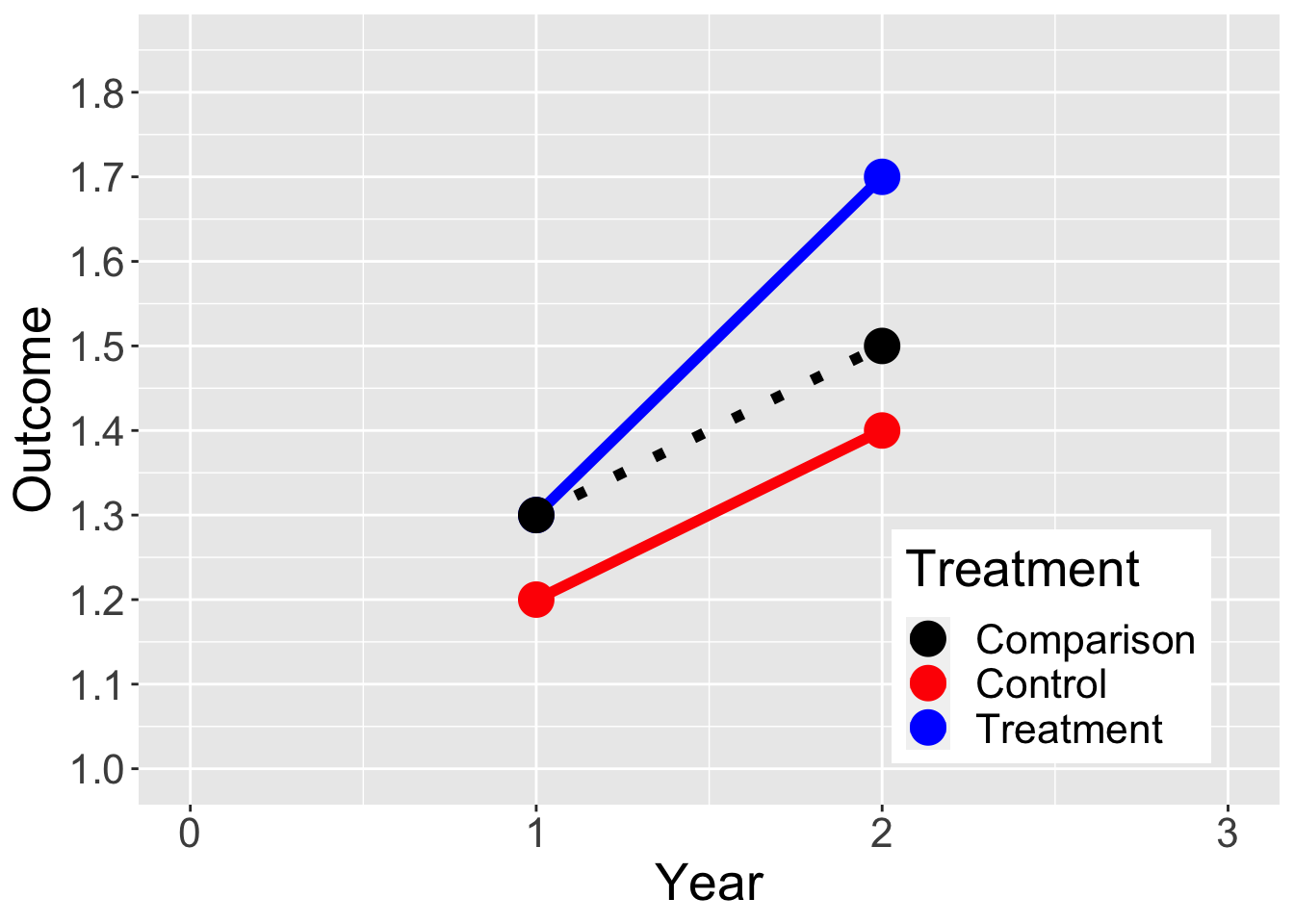

Traditional M&E focuses on implementation and outputs
Impact Evaluations focuses on theory of change and outcomes
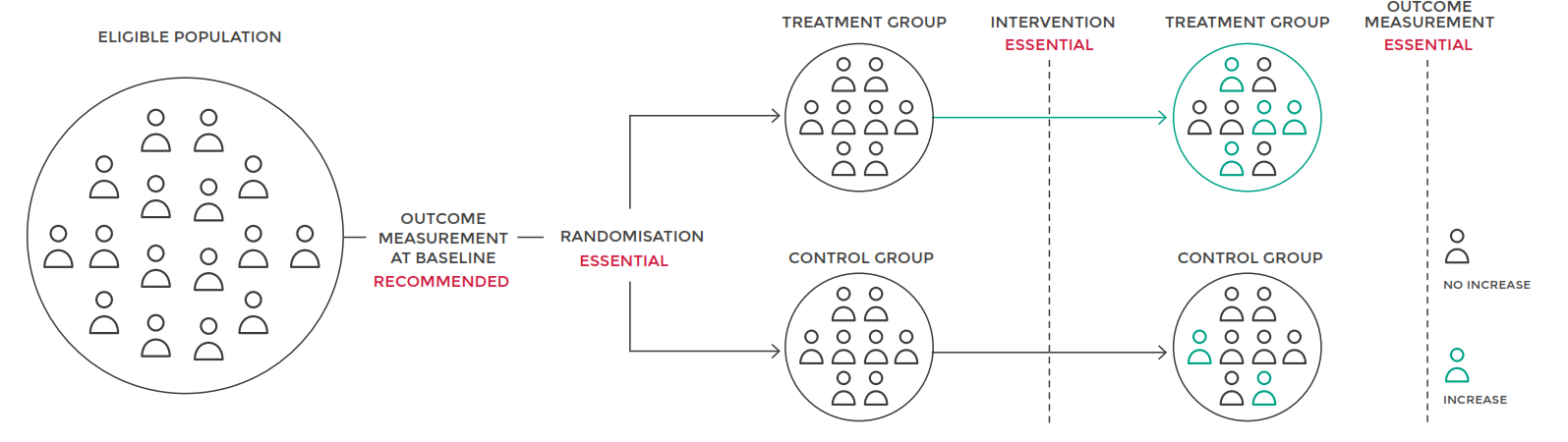
Randomization Reduces Risk of Systematic Bias
Three categories of economists:
“Scientists design general frames, engineers turn them into relevant machinery, and plumbers finally make them work in a complicated, messy policy environment.”
Example of water connections:
Why focus on details?