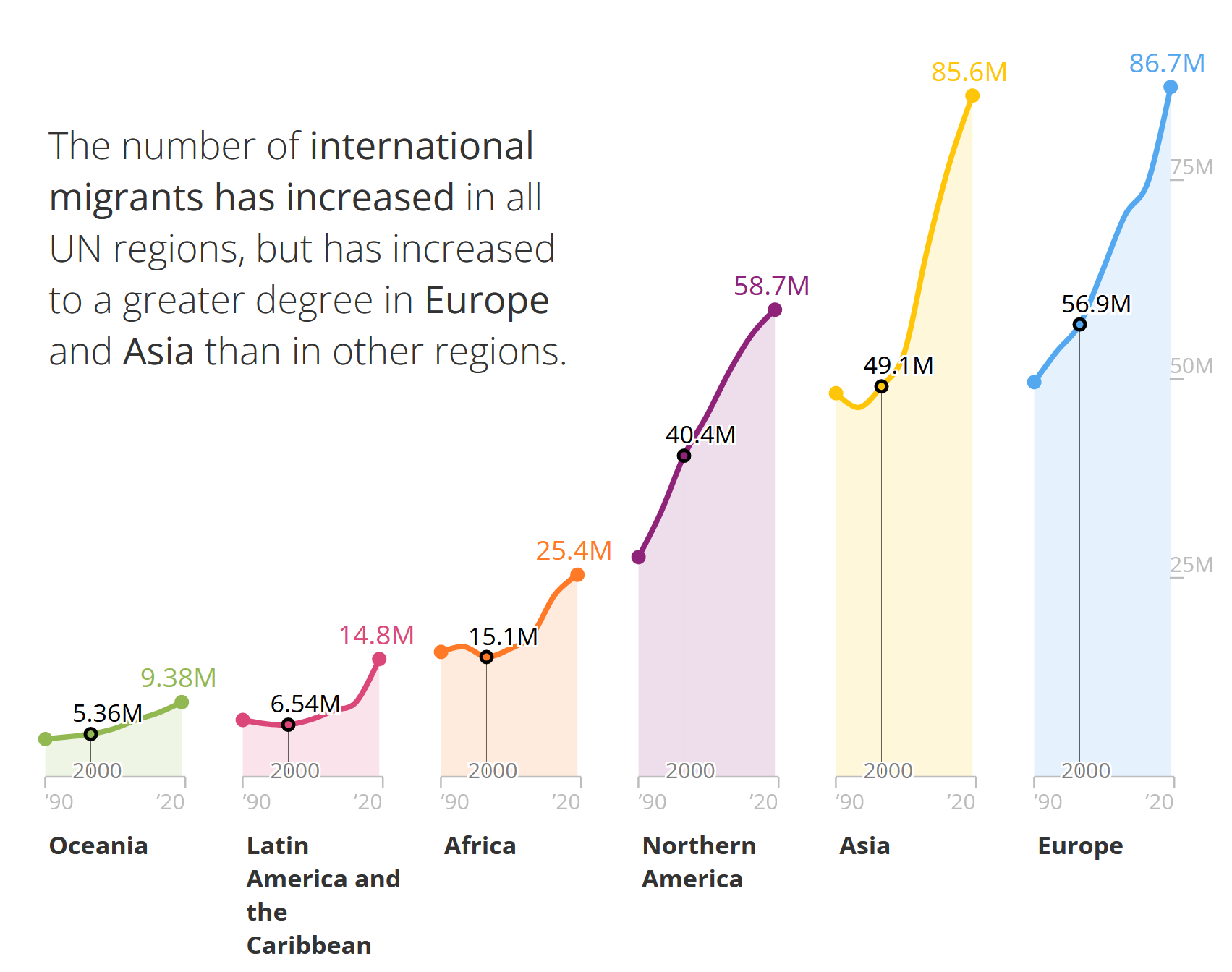
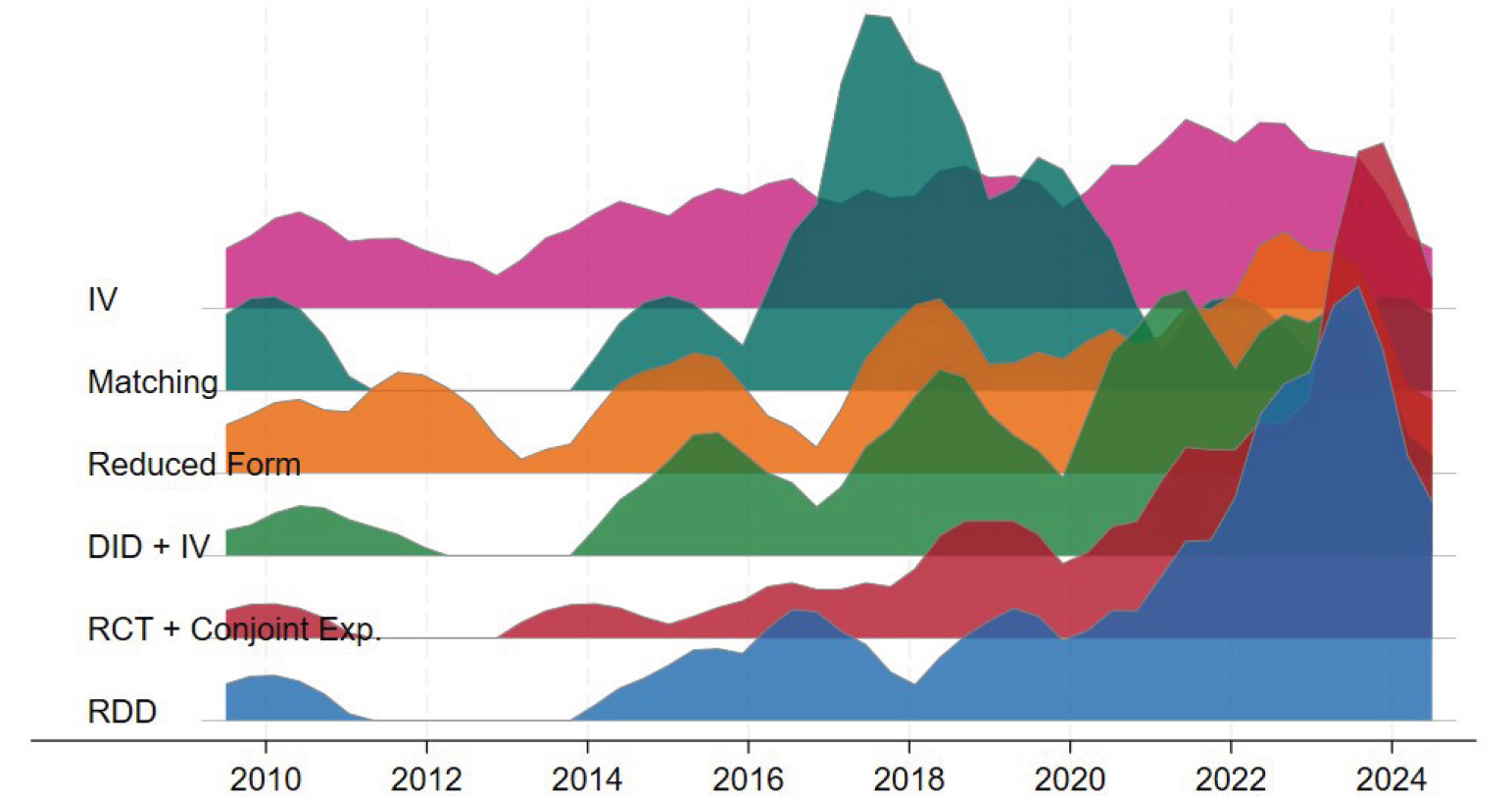
# Summarize the outputmodelsummary(list(lm(outcome ~ treatment + post, data = data),# standard modellm(outcome ~ treatment * post, data = data)), # difference-in-differences modelestimate ="{estimate}{stars} ({std.error})",statistic =NULL,gof_omit ='IC|RMSE|Log|F|R2$|Std.')
Model 1
Model 2
(Intercept)
11.475*** (0.466)
12.155*** (0.531)
treatment
−0.208 (0.538)
−1.570* (0.751)
post
−1.809*** (0.538)
−3.171*** (0.751)
treatment × post
2.723* (1.062)
Num.Obs.
200
200
R2 Adj.
0.045
0.072
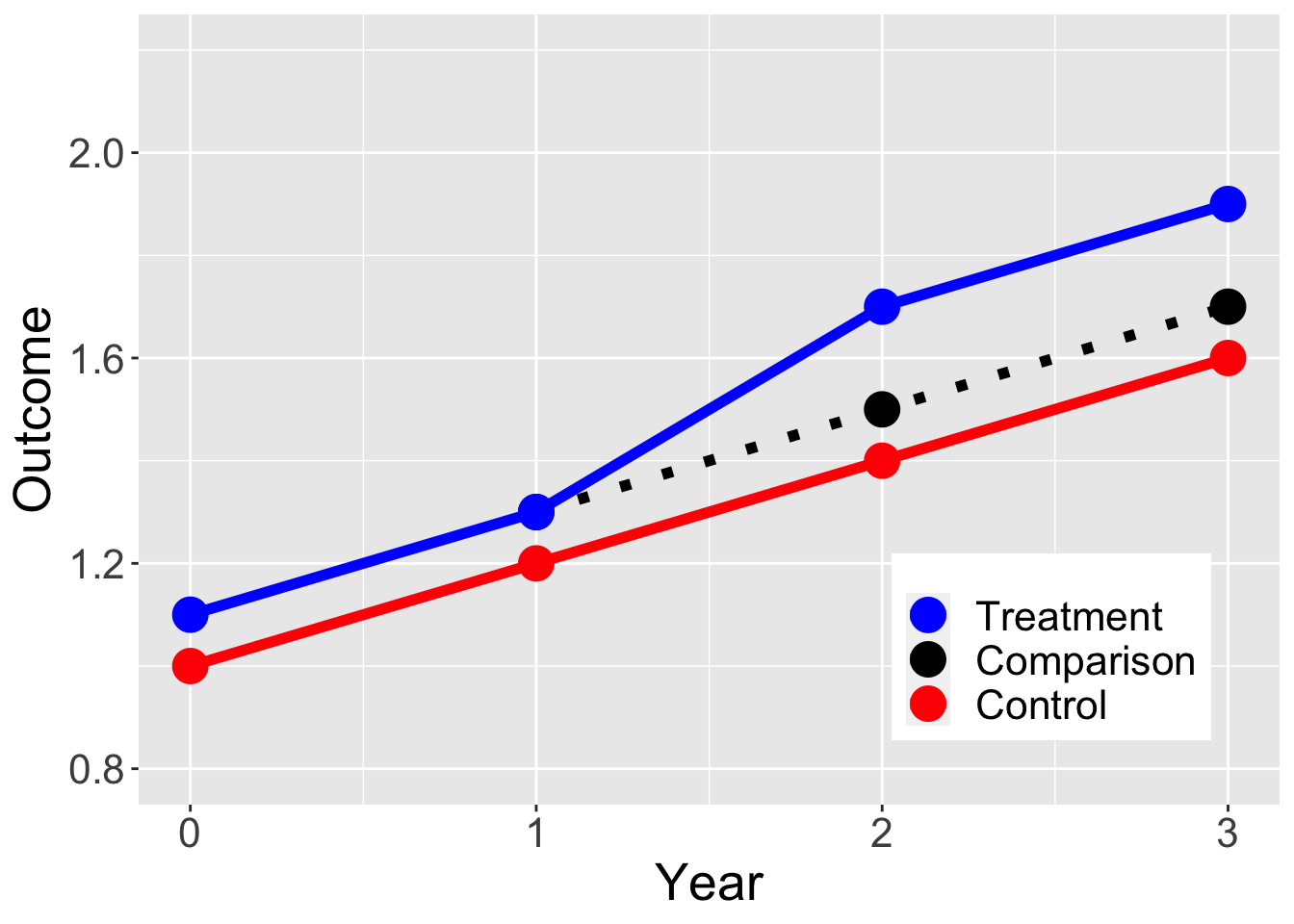
DiD: Assumptions
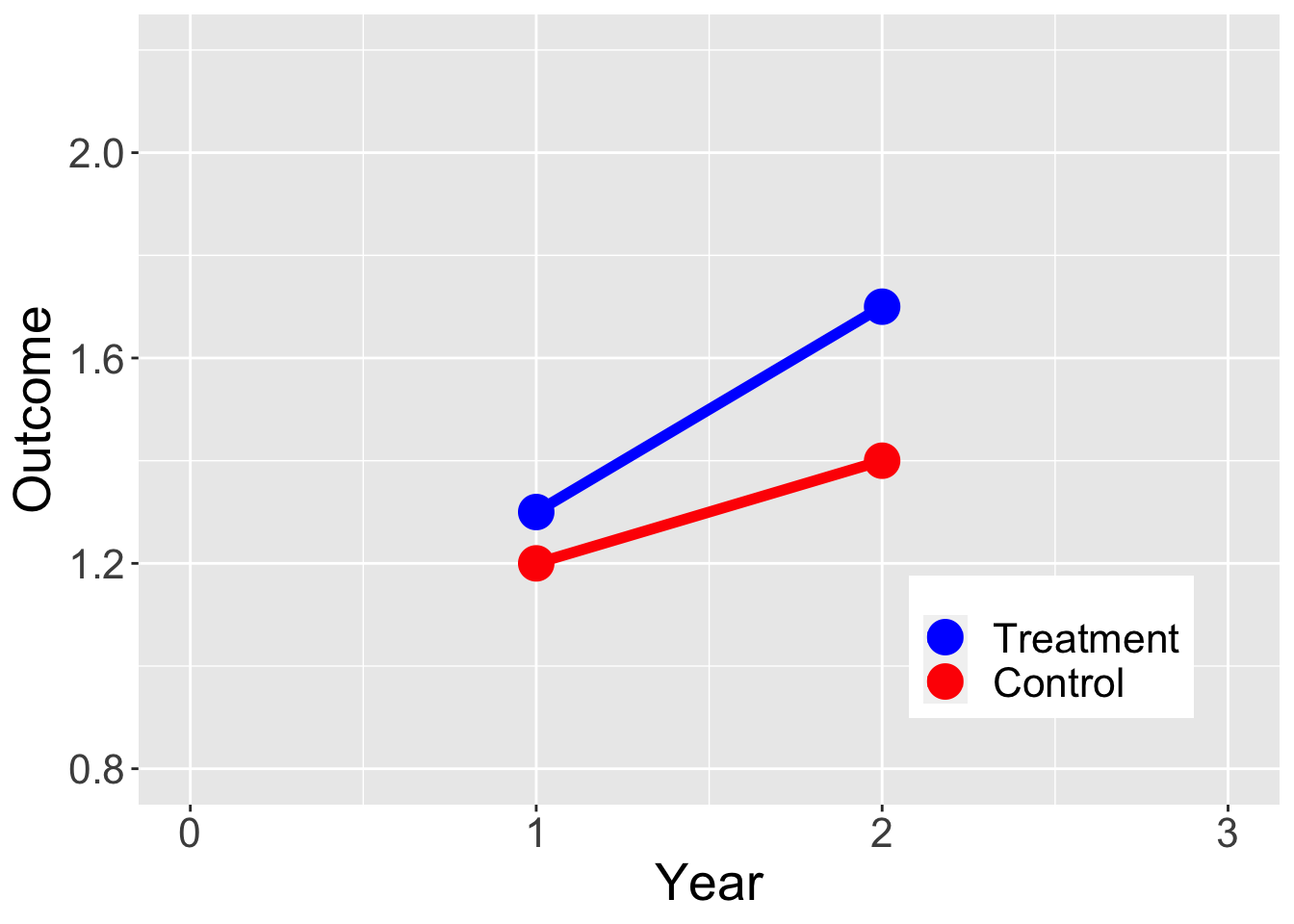
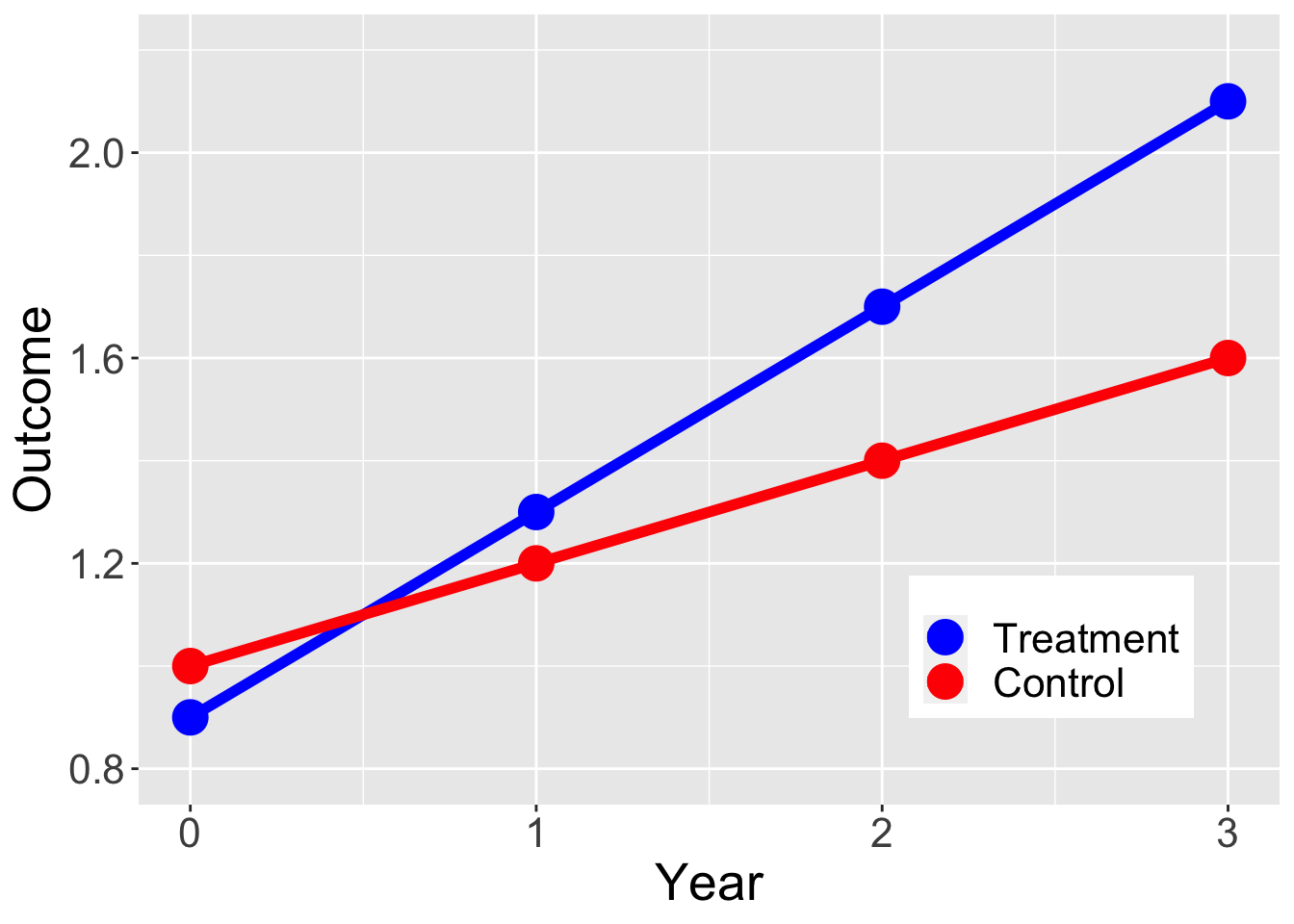
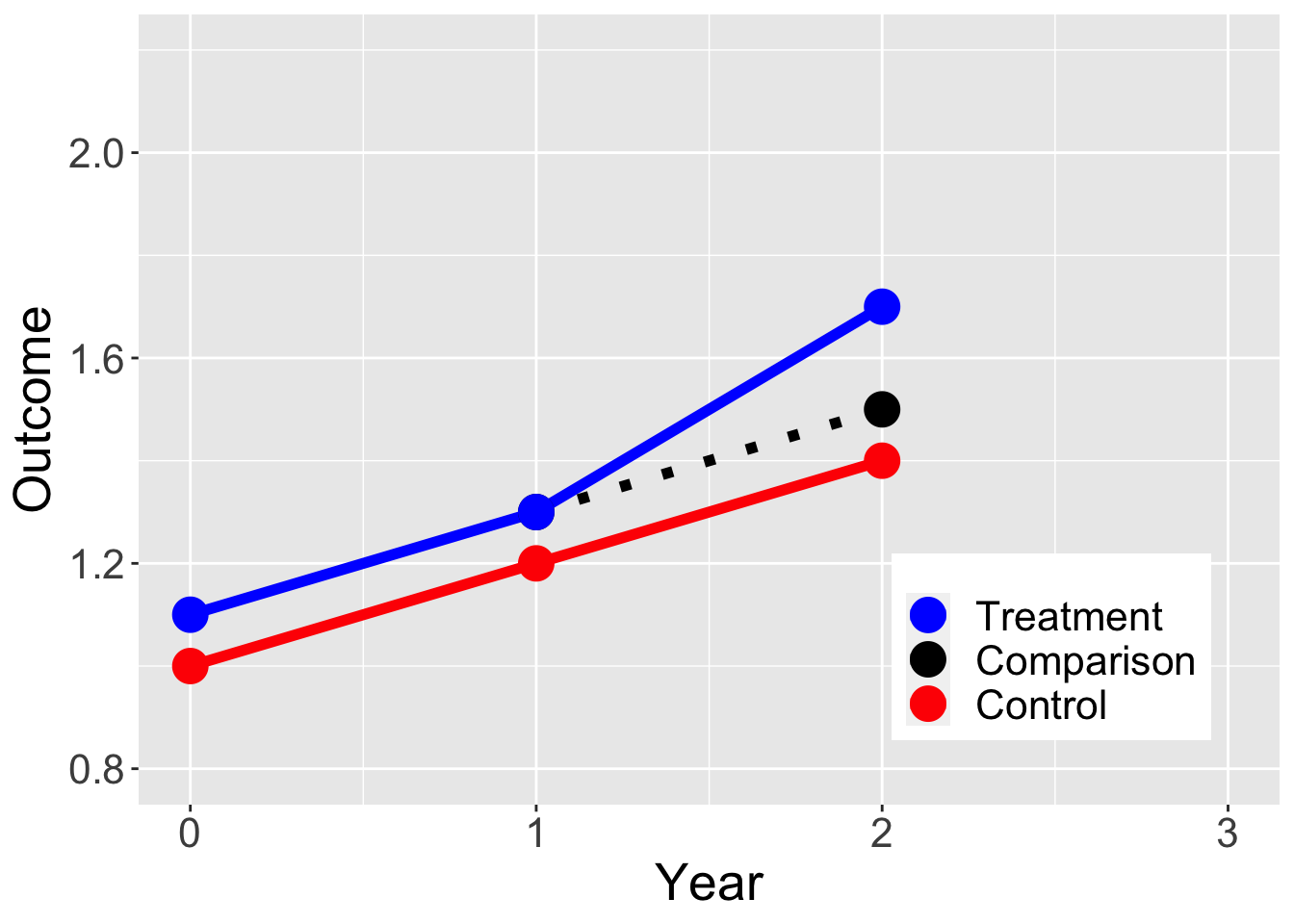
Treatment and control units would have changed in similar ways
Parallel trends
Requires at least 3 observation periods
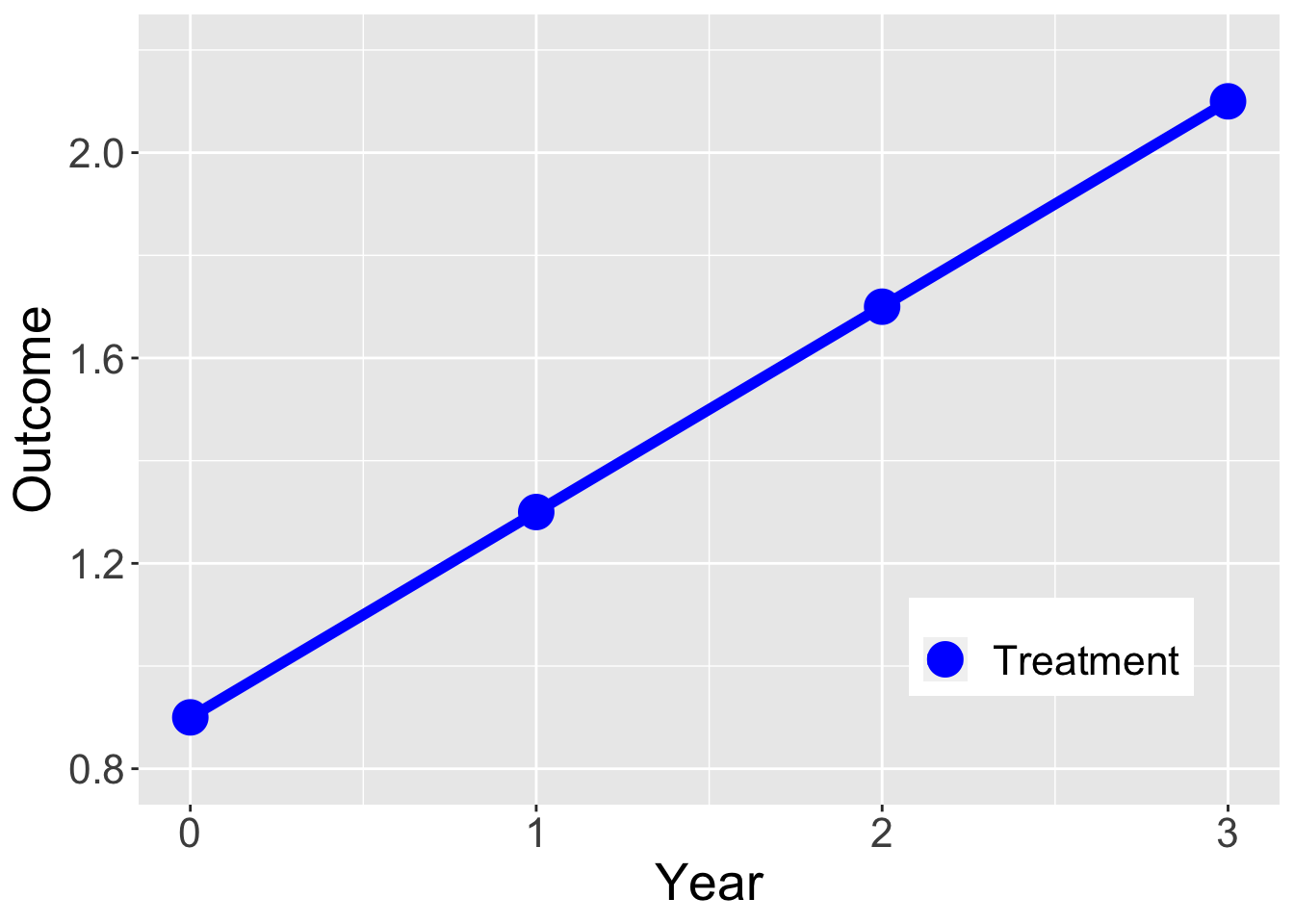
Why can’t we just observe how units change over time?